
最近,我们发布了 OpenTofu 注册中心搜索 的测试版,这是一个用户界面,可以让您搜索和查看 OpenTofu 注册中心中提供商和模块的文档。随着这个重要里程碑的达成,现在终于是时候谈论 OpenTofu 注册中心和搜索在幕后的工作原理以及运行公共注册中心的陷阱了。
注册中心 API
OpenTofu 及其前身 Terraform 依赖于社区创建的提供程序二进制文件来与各种 API 进行交互。目前 OpenTofu 注册中心中有超过 4,000 个这样的提供程序,支持从云提供商到管理您的 GitHub 帐户的各种集成。任何具有 API 来创建某种资源的东西都可以与 OpenTofu 集成。
除了提供程序之外,社区还创建了超过 20,000 个可重用的模块,这些模块实现了更高级的功能,例如仅使用几个配置选项就能使用云提供商配置整个基础设施。
由于这些提供程序和模块是由社区创建的,因此 OpenTofu 需要知道在哪里下载它们以及哪些版本可用。这就是注册中心发挥作用的地方:它保存有关可用提供程序和模块的信息、下载 URL、校验和以及用于完整性验证的 GPG 密钥。
步骤 1:服务发现
对于提供程序和模块,OpenTofu 首先请求 https://registry.opentofu.org/.well-known/terraform.json 文件,该文件包含以下内容
{
"modules.v1": "/v1/modules/",
"providers.v1": "/v1/providers/"
}
此文件列出了 OpenTofu 应该查询以获取有关模块和提供程序信息的目标端点。对于私有注册中心,还有一个名为 login.v1 的第三个端点,提供有关用于身份验证的 OAuth 端点的信息。如果您对详细信息感兴趣,您可以阅读更多关于此协议的信息 在 OpenTofu 文档中。
步骤 2:版本列表
有了端点信息,OpenTofu 就可以查询目标端点以获取所需提供程序或模块的版本列表。
- 对于提供程序,该端点将是
/v1/providers/NAMESPACE/NAME/versions(示例)。 - 对于模块,该端点将是
/v1/modules/NAMESPACE/NAME/SYSTEM/versions(示例)。
步骤 3:下载信息
根据接收到的信息,OpenTofu 可以请求有关特定版本、操作系统和体系结构的信息。
- 对于提供程序,它将位于
/v1/providers/NAMESPACE/NAME/VERSION/download/OS/ARCH(示例)。 - 对于模块,它将位于
/v1/modules/NAMESPACE/NAME/SYSTEM/VERSION/download(示例)。
然后,OpenTofu 从提供的 GitHub 版本 URL 下载提供程序,并验证校验和和签名,或为模块克隆返回的 Git 存储库。
托管注册中心(免费)
作为一个小核心团队致力于开发 OpenTofu 本身的开源项目,至关重要的是,我们将运行注册中心的成本保持在尽可能低的水平,无论是在带宽方面还是在人力成本方面。但是,我们还需要确保注册中心的正常运行时间接近 100%,因为如果注册中心出现故障,成千上万的开发人员将无法更新他们的基础设施。
在此,我们要特别感谢 Cloudflare。他们的 R2 价格非常有竞争力,没有出站费用,并且他们赞助了 OpenTofu,这意味着我们可以基本上免费运行注册中心,无需担心服务器和扩展问题。 注册中心代码库(用 Go 编写)预先生成上面 API 的所有可能答案,并将静态文件上传到 R2 存储桶中。
填充注册中心
随着 Terraform 许可证变更,HashiCorp 关闭了 Terraform 注册中心,不再支持非 Terraform 软件,因此将其作为 OpenTofu 注册中心数据来源的想法也被排除。然而,由于 Terraform 注册中心完全依赖于 GitHub,我们可以相对直接地使用 GitHub 搜索 API 来填充注册中心,即使这会有些缓慢。
然而,更新注册中心是一个更难的问题。GitHub 将 API 限制为每小时约 5,000 次请求,这不足以快速更新大约 30,000 个提供程序和模块,尤其是某些更新需要多次请求的情况下。
我们可以要求提供程序作者使用他们的 GitHub 帐户登录,为我们提供一个访问令牌,以便获得更高的速率限制,但这在注册中心发布时是不切实际的,因为我们必须在 OpenTofu 尚未发布的情况下要求数千名开发者登录。
最终的解决方案来自 GitHub RSS 订阅,它不受速率限制。位于 http://github.com/USERNAME/REPO/releases.atom 的版本 RSS 订阅总是包含最近的 5 个版本,如果我们只需要添加最新版本就足够了,因为不太可能在一个小时内出现提供程序或模块有超过 5 个版本的情况。对于模块,我们需要查询标签而不是版本,这更简单,因为 git ls-remote 命令可以提供所有这些信息,并且也不受速率限制。(GitHub,你会一直保持这种方式,对吗?)
提交流程
由于我们不需要使用 OAuth 要求提供程序和模块作者提供他们的凭据,因此我们能够创建一个简单的提交流程,任何拥有 GitHub 帐户的人都可以使用。
虽然任何人都可以提交提供程序或模块,但我们仍然需要提供程序作者提交他们的 GPG 密钥,以便验证他们的二进制文件。我们再次决定以创造性的方式使用 GitHub API,而不是要求 OAuth 登录。为了提交提供程序的 GPG 密钥,作者需要将其组织成员身份设置为提供程序存储库的公开状态,然后提交一个 GitHub 问题。我们会验证他们是否为提供程序组织的成员,并处理他们的 GPG 密钥。
将提交流程简化为提交 GitHub 问题非常受欢迎。迄今为止,社区在注册中心存储库中提交了近 1,000 个拉取请求和问题。这也意味着在大型组织工作的提供程序和模块作者不需要花费任何组织资源来注册 OpenTofu 帐户,从而导致许多知名提供程序添加了他们的 GPG 密钥。
您想了解更多关于 OpenTofu 注册中心早期发展的信息吗?来自 OpenTofu 团队的 James 和 Arel 在 2024 年 Kubecon 的 OpenTofu 日发表了关于此主题的演讲。
构建用户界面
在完成注册中心的工作并花几个月时间专注于 OpenTofu 本身的开发后,我们回到了构建搜索和文档阅读界面的工作中。很快我们就意识到,这是一项更大的任务,需要编写三倍的代码量。
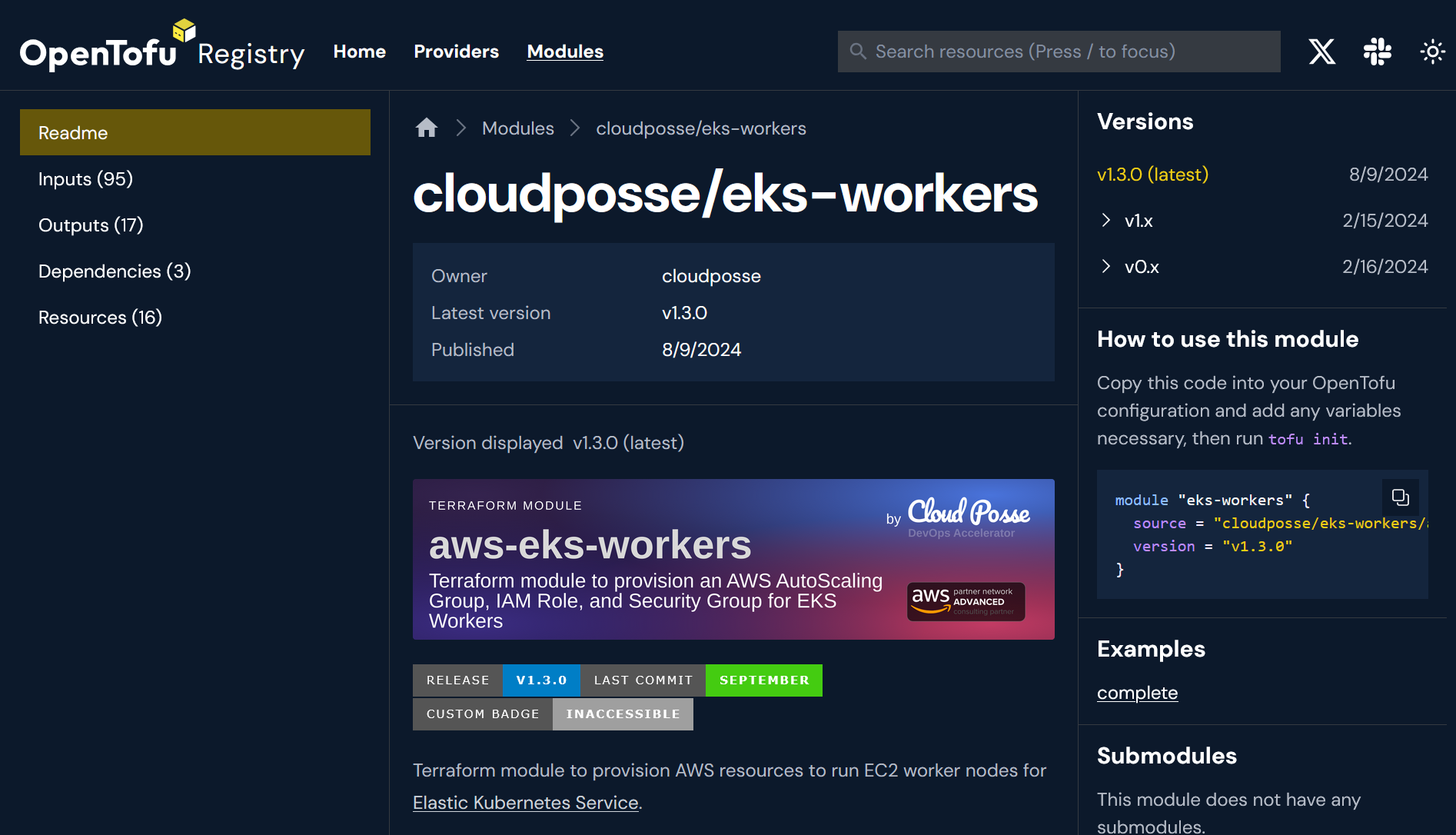
与之前一样,我们选择了一种能够生成静态文件的架构。在早期阶段,我们必须在生成静态 HTML 文件和使用单页应用程序从 API 加载数据之间做出选择。我们选择了后者,因为我们担心布局变更会需要重新生成所有文件,而这对于反复上传将是高昂的成本。
做出这一决定后,我们开始构建后端和前端组件,前者负责生成后者将使用的 数据。我们构建了 libregistry,这是一个标准化的 Go 库,它可以更轻松地访问存储在注册中心存储库中的元数据,并在 GitHub 和我们构建的用于获取数据的各种创意 API 集成之上提供一个有用的抽象层。
预处理文档
虽然注册中心总是从原始元数据重新生成所有 API 响应,但这种方法对于文档来说是不可行的,因为我们需要处理大量的数据。我们不仅需要为数万个提供程序和模块生成文档响应,而且其中一些还拥有数百个版本,每个版本都需要存储自己的文档副本。
我们决定直接从源存储库中处理数据并将其上传到一个 R2 存储桶,而无需存储任何中间数据。这种方法也带来了自己的问题。虽然注册中心可以使用 git 来跟踪中间数据的变更,但我们需要确保我们对 R2 存储桶的上传尽可能接近原子操作,这样就不会留下任何部分上传。虽然我们已经实现了可以 继续上传的部分解决方案,但这仍然是注册中心中尚未解决的问题之一。
为了简化显示文档所需的 frontend logic,后端的主要工作是将每个文档文件重命名并移动到其标准化位置。没有正式描述提供程序如何存储其文档,因此提取此信息的 logic 仅 通过经验来了解。当我们扩展了我们所接入的存储库数量并发现越来越多的边缘情况时,我们需要进行多次迭代才能解决各种 bug。
模块模式
虽然提供程序通常拥有自己的显式文档(通常由像 terraform-docs 这样的工具生成),但模块没有这种信息。这使得生成关于其输入、输出和依赖关系的信息变得很困难。
HashiCorp 发布了 terraform-schema 用于提取此信息,复制了 Terraform 中的一些模块解析 logic。然而,我们认为维护重复的代码库可能会导致维护问题,因此将此功能直接集成到 OpenTofu 中。这个补丁目前 位于一个分支上,但将在稍后作为实验性功能集成到主分支中。
许可证
在接入过程中,我们还需要考虑许可证:由于我们不确定这种文档数据集将遵循什么法律标准,因此我们特意选择了一套 有限的许可证,这些许可证我们将接受到注册中心文档中。我们对每个提供程序和模块存储库执行了自动许可证检测,以避免接入潜在问题许可证下的内容。
OpenTofu 文档 API(以及如何使用它)
对后端进行所有这些工作并将显示 logic 与数据分离也产生了一个意外但非常受欢迎的副作用:我们能够提供 用于提供程序和模块文档的 API,这将在几周后派上用场,当时 Jetbrains 要求为他们的 OpenTofu 集成提供这样的 API。
后端以这种格式生成数据集,并且可以轻松地在本地从 registry-ui 存储库运行,而 公共 API 可供任何人使用,以构建集成。我们甚至确保包含正确的 CORS 标头,如果您想构建仅限浏览器的集成。如果您构建了一些很酷的东西,请告诉我们!
搜索
当我们构建后端时,一个问题一直在我们脑海中:如何让如此庞大的数据集可搜索?我们希望能够简单地生成一个搜索索引,让客户端 JavaScript 处理整个搜索问题。当我们查看 lunr.js(一个强大且成熟的搜索库)时,我们很快意识到这条路是完全不可行的。即使是使用有限的数据集,搜索索引的下载大小也会迅速膨胀到数百兆字节,对于快速搜索功能来说并不理想,更不用说让那些有数据限制的人感到困扰了。
为了避免运行我们自己的数据库服务器或引入更多服务依赖,我们考虑了Cloudflare 的 D1,一个 SQLite 数据库服务,以及一个worker来处理搜索查询。虽然它最初看起来很有希望,但我们发现,为了在一个事务中运行更新,我们必须在单个 HTTP 请求中提交所有更新。
虽然可以找到解决方法,并仍然执行原子搜索索引更新,但最终我们使用了Neon,一个数据库即服务产品。他们没有明确赞助 OpenTofu,但他们的免费层足以满足我们的搜索索引需求,下一层也非常实惠。他们与 Cloudflare 的紧密集成也是一个非常受欢迎的补充。
为了查询托管在 Neon 上的数据库,我们创建了一个 Cloudflare worker。这个 worker 最终负责处理所有对 api.opentofu.org 的请求,将静态请求转发到 R2,并自行处理搜索查询。
后端将准备一个包含所有最近搜索索引更新的行分隔 JSON(ndjson)文件数据提要,位于https://api.opentofu.org/registry/docs/search.ndjson,worker 可以获取这些更新并填充到数据库中。
我们下一步要做什么?
OpenTofu 注册中心搜索目前处于测试阶段,这意味着并非所有功能都已正常运行。随着我们不断扩展索引的提供商和模块数量,我们一定会发现更多需要修复的边缘情况。
libregistry 库也重复了注册中心代码库中存在的大量功能。我们希望消除这种重复功能,这有利于长期的维护,也因为 libregistry 将使人们更容易运行他们自己的镜像甚至注册中心的独立副本。
在此过程中,您的反馈对优先排序至关重要。如果您发现错误或遇到我们尚未考虑的用例,请使用GitHub 问题告知我们。